1. 引言
随着全球信息化以及网络技术的迅速发展,针对特定攻击对象的有组织的高级持续性威胁(Advanced Persistent threat, APT)日益增多,带来的后果愈发严重,许多企业甚至国家的信息安全都受到严重威胁 [1] [2] [3] 。2008年,来自美国国防部的黑客攻击渗透中国长城网;2010年,“震网”病毒成功攻击了伊朗的工业控制系统,导致了伊朗核计划的推迟;2011年,“夜龙行动”窃取了多个能源巨头公司的核心敏感文件;2012年,“火焰”成功获取中东各国的大量机密信息。由此可知,APT攻击对于国家网络空间主权、工业控制系统以及企业数据的信息安全具有十分恶劣的不良影响与巨大的威胁,因此,亟需针对APT攻击进行有效的检测与防护。
APT攻击是长期的、持续性的网络攻击,攻击行为藏匿在正常行为中难以被发觉。因此,攻击检测成为APT攻击防御工作中最关键而且最困难的部分。然而,传统的攻击检测技术无法有效处理数据量极大的数据记录集。此外,传统的攻击检测技术往往只能识别检测出较为明显的异常或攻击行为,用来检测隐匿在正常行为中的APT攻击并不能得到理想的检测结果。所以,传统的攻击检测技术大多无法有效检测APT攻击 [4] 。现有的APT攻击检测方案分沙箱方法、异常检测方法和全流量审计方法 [5] 三种。沙箱方法主要解决特征匹配对新型攻击的滞后性问题。该方法将实时流量引入沙箱中,通过对沙箱中的文件系统、网络行为、进程、注册表实施监控,检测是否存在恶意代码。异常检测方法可以解决特征匹配和实时监测的不足,通过对网络中的正常行为模式建模从而识别异常行为。全流量审计方案也是为了解决传统特征匹配不足而提出的,该方法对链路中的流量进行深层次的协议解析和应用还原,识别其中是否包含攻击行为。在这三种方法中,异常检测与全流量审计都需要处理海量数据,因此APT攻击检测的模型应适用于数据量极大的情况。
深度学习模型是一种多处理层的计算模型,通过组合多层非线性的简单模块来实现多层表征学习,每层都会从上一层的简单表征里学习更抽象复杂的表征,从海量高维的原始数据中识别出复杂的模型。所以,研究人员已经开始探索深度学习在网络异常检测中的应用。
目前,利用深度学习模型 [6] 对网络中的APT攻击检测技术研究主要包括以下三个方面:无监督学习、监督学习和半监督学习。无监督学习直接学习数据的内在结构,无需样本的标签数据,不需要对样本进行大量标记,但检测率较低。Kingsly等人 [7] 提出以基于聚类算法的网络异常检测方法,将网络数据通过聚类分为若干组,根据这些分组识别每条数据是否为正常数据。有监督学习需要提前对训练样本进行标记,该方法首先使用有标签的训练集学习分类器,然后使用学习后的分类器对网络行为做识别检测。文献 [8] 提出将支持向量机(Support Vector Machines, SVM)方法应用到APT攻击检测中。除此之外,朴素贝叶斯(Naïve Bayes, NB) [9] 、遗传算法(Genetic Algorithm, GA) [10] 也都应用到入侵检测领域。有监督学习的方法往往表现出优异的检测效果,然而需要对样本进行标记后再训练,对于数据量大的数据集不具有较高的实用性。半监督学习是监督学习与无监督学习相结合的一种方法,该方法主要考虑利用少量的标注数据和大量的未标注数据进行分类 [11] [12] 。Yasami等 [13] 利用k-means聚类和ID3决策树学习算法进行网络异常的检测,首先利用k-means对训练集进行训练,再使用ID3决策树检测判断是否发生异常。文献 [14] 提出基于深度信念网络(Deep Belief Networks, DBN)和支持向量机(Support Vector Machines, SVM)的混合模型进行网络入侵检测。
针对数据属性数量较多、维度较高的问题,Rubinstein等人 [15] 提出使用主成分分析法提取出主分量,选择重要的主成分对数据进行结构降维。针对结构降维问题,还有文献 [16] [17] [18] 提出可以使用DBN(Deep Belief Networks, DBN)进行结构降维。通过结构降维的方法,深度学习模型利用学习低维特征能够很好地解决传统机器学习面临的“维数灾难”,并且有效地提高了深度学习模型的训练时间和测试时间,具有较高的检测效率,在高维复杂的网络数据中取得了较好的检测效果。
根据上述分析,本文提出一种基于半监督学习的APT攻击检测方法。首先采用无监督学习的DBN [16] 进行初步的降维与分类,然后在DBN算法的基础上,使用SVDD算法进行进一步的训练与检测。实验结果表明,本文提出的方法在攻击检测中具有较高的准确率,能够有效地检测网络异常行为,利用该方法检测APT攻击具有一定的可行性。同时,该算法相较于基于监督学习的异常检测而言,不需要大量经过标记的样本;相较于无监督学习的异常检测而言,具有较高的检测准确性。
本文组织如下:第二部分介绍基于半监督学习的网络异常检测模型,第三部分介绍相关实验步骤及实验结果分析,第四部分对本文进行总结。
2. 基于半监督学习的APT检测模型
2.1. 深度信念网络DBN
2006年Hinton等人 [17] 提出深度信念网(Deep Belief Net, DBN),它是由多层无监督的限制玻尔兹曼机网络和一层有监督的反向传播网络组成,结构如图1所示。
DBN是一种无监督学习的方法,目前已被建议作为一个多层次分类器和降维工具。DBN多层生成模型,学习一个层的特性与未标记的数据,后提取的特征作为输入的训练下一层。这种高效的学习可以通过微调后的权重提高整个网络的性能。该方法适用于数据量大且高维的数据集,对于APT攻击的检测具有很高的实用价值。
DBN使用未标记的数据、一次学习一层特征的多层生成模型。DBN具有对于数据量庞大的数据集执行非线性维数降低的能力和对高维流形数据的学习能力,可以使用受限玻尔兹曼机(Restricted Boltzmann Machines, RBM)以多层方式高度训练。
在RBM中可见单元v为表示特征,隐藏单元h学习表示特征,即它将来自维度为n的输入空间的输入向量v映射到维度为
的特征空间里,其中
。给定数据集
作为输入,RBM将其映射到
中。在RBM中,相同级别的单元之间没有连接,即可见–可见或隐藏–隐藏连接,并且图的两层用隐藏和可见单元对之间的对称权重W连接。
在原始的玻尔兹曼机器架构中,隐藏和可见向量的联合分布
是根据能量函数
定义的,假设输入向量是具有方差
的高斯随机变量,则该高斯伯努利RBM的能量函数
可以被获得为:
(1)
其中
和
分别是具有
的对称权重的可见v层和隐藏h层的第i和第j个单元,以及相应的偏差
和
,因此
的公式如下所示:
(2)
其中Z是称为分区函数的归一化因子,并且计算为:
(3)
联接配置的值由相对于网络参数的值
来确定,其中b和c分别是对隐藏层和可见层的偏差。隐含层h是二进制的,并且隐藏单元是伯努利随机变量,而输入单元可以是二进制或实值。给定二元隐藏单元
,由于隐藏单元之间没有连接,所以可以直接计算条件分布
:
(4)
并且类似地,由于在可见单元之间没有连接,因此:
(5)
其中:
(6)
是逻辑S型函数和
表示具有均值
和方差
的高斯分布。训练RBM意味着找到参数θ的值,使得能量最小化。一种可能的方法旨在最大化由其相对于模型参数的梯度估计的v的对数似然:
(7)
由于对数似然的第二项的精确计算是难以处理的,所以可以使用称为对比度发散(CD) [19] 的方法来估计梯度。CD近似通过k次迭代的吉布斯采样(通常k = 1)的期望以更新网络权重:
(8)
其中
表示对比发散迭代I的平均值。在训练RBM之后,另一个RBM可以堆叠在第一个RBM的顶部,即隐藏单元的推断状态
用作用于培训新的RBM的可见单位。上层可以是伯努利伯努利RBM,其中与第一层的主要区别在于二元可见单位和能量函数 [20] 。堆叠RBM使得人们能够建模早期RBM的隐藏单元之间的显着依赖性。更具体地,可以堆叠多层RBM以产生不同层的非线性特征检测器,其表示数据中逐渐更复杂的统计结构。在RBM的堆栈中,所得DBN的自底向上识别权重被用于初始化多层前馈神经网络的权重。该网络可以用作用于降维的工具,或者用逻辑回归层来顶端并且通过用于分类的反向传播来进行区别地微调。
2.2. 支持向量数据描述方法SVDD
支持向量数据描述方法(Support Vector Data Description, SVDD)是由Tax等人结合SVM方法与最小包围球而提出的一种数据描述方法。其主要思想为在高维特征空间中找寻一个尽可能将所有训练样本都包围起来的最小超球体,并以这个最小超球体的决策边界对数据进行分类和描述。由于SVDD对异常点十分敏感,所以常常用于处理异常检测等问题,且SVDD相较于SVM而言具有训练速度快等特点。
SVDD需要在高维特征空间中找寻一个尽可能将所有训练样本都包围起来的最小超球体,实际情况下数据并不是集中分布,因此往往会引入一个松弛变量 [21] 。所以很清楚地可以知道求解最小超球体的问题可以描述为:
(9)
其中C为一个常数,是对错误分类样本的惩罚程度,K也是用户指定的一个常数,一般情况下K = 1,并且上述问题描述应该满足约束条件:
(10)
a为要构造的超球体的球心向量,利用其中半径的计算公式为:
(11)
2.3. 基于半监督学习的攻击检测方法
图2为DBN-SVDD模型图,该模型图分为三部分:数据预处理、DBN训练阶段、SVDD识别检测阶段。其中数据预处理分为字符型属性映射和数据属性归一化。NSL-KDD数据集的每一条数据记录有38个数字型特征和3个字符型特征,因此需要先将字符型属性映射成数字型属性。由于数据本身的定性特征没有明显的顺序,故采用哑编码进行映射。又因为特征向量中每一个特征量纲不同,取值范围不一,所以需要对数据属性归一化。
在这里我们选择开源框架keras建立DBN网络,keras是一个高层神经网络API,keras由纯Python编写而成并基于Tensorflow、Theano以及CNTK后端。keras为支持快速实验而生,能够把你的idea迅速转换为结果。
在DBN训练阶段,得到标准数据集以后,我们使用DBN模型对其降维。低层RBM进行初步降维以后再使用高层RBM从低层RBM传来的简单表征里学习更抽象复杂的表征,并反向调整权值,提取出特征优秀的数据。再将DBN处理过的数据分为训练集和测试集,提供数据记录给SVDD进行训练和识别检测,最终得到检测结果。该攻击检测方法的具体步骤如下:
步骤1:使用哑编码做字符型属性映射
步骤2:对步骤1处理过的数据属性进行归一化
步骤3:使用keras开源框架建立DBN网络
步骤4:使用DBN网络进行降维和提取优秀的特征向量
步骤5:构建SVDD网络
步骤6:对训练集进行训练
步骤7:对测试集进行仿真和测试
该实验流程如图3所示。
3. 仿真与实验
3.1. 实验环境与评价指标设计
本文对提出的基于半监督学习的攻击检测模型进行仿真实验。采用的数据集为NSL-KDD数据集,该数据是KDDCU99的改进版,包含了KDDTrain+、KDDTrain_20percent、KDDTest+和KDDTest-21四个子数据集,其中它们分别有125,973、25,192、22,544、11,850条数据记录。
该仿真实验在Ubuntu 6.04LTS环境下进行,使用Keras神经网络库、Sklearn机器学习包构建DBN-SVDD网络,并且使用Tensorflow 0.8作为后端计算框架,DBN层数设置为2层,低层RBM将41个特征降维成13个特征,高层RBM将13个特征价格为成5个特征。测试机的配置如表1所示。
为了评价与比较相关的攻击检测模型,本文采用的是检测率和测试时间这两个性能指标。其中检测
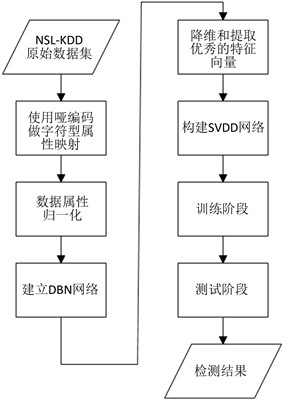
Figure 3. Experimental flow chart of DBN-SVDD
图3. DBN-SVDD实验流程图

Table 1. The detailed configuration information of testing machine
表1. 测试机详细配置
率是指检测到的异常数据样本和实际的异常数据样本的数据比率,测试时间是指测试数据所花费的时间,该指标可以反映在实际应用中模型的运行时间。
3.2. 数据预处理
NSL-KDD数据集的每条记录都包括了三方面的特征信息,1~9为基本信息特征,10~22为内容特征,23~31为基于时间的流量特征,32~41为基于主机的流量特征 [22] 。训练集中包含了22种攻击,为了模拟实际情况中有一些新的攻击出现,测试集中包含了17种训练集中没有出现过的攻击类型。而所有攻击数据主要可划分为以下四类攻击:拒绝服务攻击(DoS)、远程网络用户攻击(R2L)、提升权限攻击(U2R)和探测攻击(Probe)。其中DoS攻击为APT攻击的主要攻击方式之一。
由于NSL-KDD每条实验记录不仅有38个数字型属性特征,还有protocol_type、service、flag这3个字符型属性特征,其中protocol_type有3种特征值,service有70种特征值,flag有11种特征值,因此我们需要将原始记录中字符型特征进行映射转换成数字型属性。本文使用哑变量(Dummy Variables) [23] 编码的方式对这3种字符特征进行编码,将每一条原始的数据记录变成一个122维的特征向量。
由于特征向量中每一个特征量纲不同,取值范围不一,所以我们需要对每个特征向量进行标准化(Standardization or Mean Removal and Variance Scaling),变换后各维特征有0均值,单位方差。也叫z-score规范化(零均值规范化)。计算方式是将特征值减去均值,除以标准差。本文在train集上做标准化后,用同样的标准化器去标准化test集。
最后,由于该数据集的攻击主要分为四类,因此我们将数据集的类标分为5类。
3.3. 实验结果与分析
3.3.1. 不同数据降维的比较
在前言中已经提到解决传统机器学习面临的“维数灾难”研究人员提出了使用结构降维的方法先对数据进行降维,其中常用的三种降维方法有PCA、GAB RATB、DBN。其中文献 [24] 提出对这3种不同的降维方法做出了不同数据降维方法间的比较。分别给PCA、GAB RATB、DBN设置了训练数据20%、40%、60%、80%的数据量。性能对比分析结果如图4所示,从以上数据可以看出DBN的降维效果相对较好,四个数据量都达到了90%以上,更加适合处理高维数据。
3.3.2. 与其他深度学习模型的比较
前言中我们已经简要阐述了用于网络异常检测的深度学习模型有聚类模型、DBN-SVM、DBN、SVM等,由于篇幅有限,不再对这些方法进行详细的阐述。接下来本小节将要阐述实验过程,然后给出实验结果最后分析出实验结论。
本文提出的方法与其他几种深度学习的方法的对比实验结果如表2所示,使用NSL-KDD数据进行模型训练时,K-means由于是无人监督的机器学习模型,因此所需时间短,但其检测率较低。本文提出来的方法其运行时间比DBN-SVM长0.48 s,但其准确率略胜DBN-SVM,达到93.71%的准确率。

Figure 4. Comparison of results of different data reduction methods
图4. 不同数据降维方法的结果对比
Table 2. Comparison with the results of other deep learning methods
表2. 与其他深度学习方法的结果数据比较
综上可以看出,本文提出的DBN-SVDD异常检测模型,相较于其他模型具有一定的优势,具有较强的潜力。该模型有以下几种优势:1) 该模型是一种无人监督的机器学习模型,不需要大量数据标记样本适用于检测海量的数据记录;2) 该模型具有较高的检测率,且其运行时间比有监督学习短但比无监督学习强,综合检测率和运行时间具有较为优秀的应用性能;3) 该模型适用于高维数据,具有突出的降维效果。
4. 结束语
本文提出了一个基于DBN-SVDD的攻击检测模型,其中DBN用于特征降维和提取优秀的特征向量,SVDD是用于数据分类与检测。通过NSL-KDD数据集的实验结果表明,DBN-SVDD拥有很好的分类效果,并且对数据的降维极大地提高了测试时间。同时,DBN比PCA具有更好的性能;此外,SVDD与SVM相比也具有很好的分类效果。该攻击检测模型适用于无人监督的数据量大且具有高维特征的攻击数据检测中,且具有优异的检测效果,十分贴合对APT攻击检测模型的需求。在接下来的工作中,我们将考虑如何降低该模型的性能开销,并进一步讨论如何提高该模型的检测率。总之,该模型极大地提高了入侵检测速度且具有优秀的检测效果,是一种可行的、高效的APT攻击检测模型。