1. 引言
随着信息技术的日新月异,信息安全问题成为了人们生活中不可分割的一部分。为了保护用户帐户、隐私和财产的安全,身份认证技术开始扮演着重要的角色。作为一种生物特征认证技术,在线签名认证(online signature verification, OSV)技术已经成为政府、法律系统、银行等部门最广泛接受的身份认证手段之一 [1]。然而,由于签名样本的不稳定性以及复杂性使得OSV技术仍面临着很大的挑战。因此,深入研究OSV技术以实现个人身份的有效认证对于在线手写签名能否赋予完备的法律效力具有重要的意义。
早期的OSV研究主要集中在传统的模式识别技术中。Fierrez-Aguilar等提出了100种在线签名的全局特征,并根据它们辨别真伪签名的能力进行了排序 [2]。Kholmatov等通过使用当前样本和所有参考样本之间的距离来为每个签名构建一个三维特征向量,提出了一种改进的动态时间规整(dynamic time warping, DTW)模型 [3]。Van等提出了一种基于隐马尔可夫模型(hidden Markov model, HMM)的在线签名认证方法,通过补充由HMM建模的似然信息和片段(维特比路径)信息,提高了在线签名认证的准确性 [4]。Sharma等使用向量量化(vector quantization, VQ)策略构建了一组编码向量,对规整路径中的对齐对进行评分,并将该评分与DTW评分融合,改善了DTW单一决策规则的不足 [5]。
近年来,随着深度学习技术的进步,基于深度学习的OSV技术也得到了应用并进一步的提高了在线签名的认证精度。Lai等将签名认证表述为序列建模问题,通过训练循环神经网络(recurrent neural network, RNN)来学习一种称为长度归一化路径签名(length-normalized path signature, LNPS)的度量方式从而表示真伪签名之间的距离 [6]。Ahrabian等使用12种签名特征序列作为自动编码器(auto encoder, AE)的输入,并使用SNN构建了独立于用户的在线签名认证模型 [1]。陆鑫益等将卷积神经网络(convolutional neural network, CNN)和长短期记忆神经网络(long short term memory network, LSTM)相融合提出了一种双通道深度神经网络模型提高了签名认证的性能 [7]。Vorugunti等将人工提取的在线签名特征与AE提取的在线签名特征进行融合,并首次将深度可分离卷积神经网络(depth wise separable convolutional neural network, DWSCNN)应用于在线签名认证任务中 [8]。
尽管深度学习技术的进步有效地提高了OSV系统的性能,但是这些基于深度学习的工作均是基于单任务学习来对网络参数进行更新的。由于每个用户所提供的签名样本量有限,这些基于单任务学习的深度学习方法并不能有效地学习到签名的判别性特征。为了解决这个问题,本文提出了一种基于多任务学习的注意力机制双向门循环单元(multi task learning-attention mechanism-bidirectional gate recurrent unit, MT-A-BiGRU)模型来实现在线手写签名的认证。本文的主要贡献如下:
首先,我们使用基于注意力机制的双向门循环单元(A-BiGRU)模型来实现在线签名序列特征的有监督学习,并引入深度度量学习任务来进一步提高网络对在线签名序列的表征学习能力。其次,引入稀疏自动编码器(sparse auto encoder, SAE)模型来对人工所提取的全局特征进行降维,并将SAE模型隐藏层中的特征向量与A-BiGRU模型所提取的特征向量进行融合,实现了不同类型特征的信息互补。最后,将三种学习任务的损失函数进行结合,提出了一种基于多任务学习的训练方法。三种学习任务相辅相成、互补优化,进一步提高了在线手写签名认证的准确率。
2. 方法
2.1. 数据收集和预处理
在数据收集中,本研究主要使用SVC-2004数据库 [9] 中第二个任务(SVC-2004-task2)的数据集来训练和评估所提出的方法。SVC-2004-task2数据集共有40个用户,每个用户的签名包括20个真实样本和20个伪造样本。本研究将每个用户的前10个真伪签名样本作为训练集,将每个用户的后10个真伪签名样本作为验证集。
在预处理阶段中,本研究首先对签名样本进行平滑和归一化处理。其次,依据文献 [10] 提取了47个能够表示签名的全局特征,如速度平均值、横纵坐标均值、平均压力等。最后,选取签名的横坐标(x)序列、纵坐标(y)序列以及压力(p)序列作为表示签名的序列特征。由于神经网络的输入数据是等长的,因此本研究通过三次样条差值算法来分别将每个用户中的真伪签名序列插值为等长。经过插值后,每个用户签名的长度等于每个用户最长签名序列的长度。
2.2. 算法总体框架
本研究所提出的基于MT-A-BiGRU模型的在线签名认证模型的总体算法框架如图1所示。该网络共包括SAE和A-BiGRU两种网络模型并通过无监督、有监督和深度度量三种学习任务相结合的多任务学习(multi task learning, MTL)方式来进行表征学习。首先,本研究将签名的全局特征和序列特征分别作为SAE模型和A-BiGRU模型的输入。其次,本研究使用A-BiGRU模型的有监督学习任务(supervised learning task, SLT)和深度度量学习任务(deep metric learning task, DMLT)来实现签名序列特征的特征提取,并通过SAE模型的无监督学习任务(unsupervised learning task, ULT)来实现签名全局特征的降维。最后,本研究将SAE隐藏层中的特征向量与A-BiGRU模型所提取的特征向量进行融合以提高网络提取判别性特征的能力。每个部分的具体信息将在后文进行介绍。
2.3. 基于注意力机制的双向GRU
传统的循环神经网络(recurrent neural network, RNN)模型因梯度消失和梯度爆炸问题而严重阻碍了学习时间序列长期依赖的能力 [11]。作为RNN模型的一种新的变体,门控循环单元(gated recurrent unit, GRU)模型能够高效的捕获时间序列上的长期依赖性。GRU模型的详细结构如图2所示。GRU模型内部包含两种结构:重置门和更新门。其中,重置门用于减少上一单元中被认为非相关的信息,更新门则用来决定上一单元有多少信息需要传递给下一单元。假设
表示第t时间的输入信息,则对应时间上的输出
如下式所示:
(1)
(2)
(3)
(4)
式中,
表示sigmoid激活函数,
,
表示重置门和更新门的输出,
,
表示候选输出和实际输出,
表示按元素相乘。双向GRU模型比单向GRU模型多了一组反方向传播的GRU模型,这使得双向GRU能够比单向GRU获取到更多信息。因此,本研究使用双向GRU来实现签名序列的特征提取。
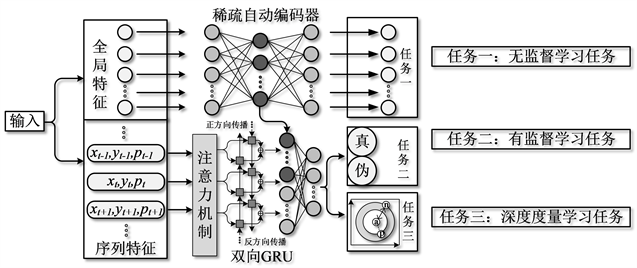
Figure 1. The overall algorithm framework of the proposed model
图1. 所提出模型的总体算法框架
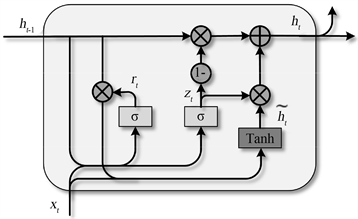
Figure 2. The detailed structure of the GRU model
图2. GRU模型的详细结构
本研究所使用的签名序列特征是由x序列、y序列以及p所组成的三通道序列特征。考虑到三通道特征序列的稳定性不同以及每个签名序列内部的特征点所蕴含的信息量不同,本研究设计了一种注意力机制层,如图3所示,并将其添加到双向GRU模型的输入端。所设计的注意力机制层首先关注于同一时间不同维度的特征信息,然后根据这些信息来对该时间点的关注程度进行建模,从而实现了网络对签名不同序列特征和签名序列内部的特征点的筛选。假设某一用户签名序列的总长度为T,注意力机制层的第t时间输入为
,则相应时间所输出的
如下式所示:
(5)
(6)
(7)
(8)
(9)
式中,
表示同一时间上的不同特征维度上的关注度,
表示t时间上的不同特征维度的内在信息,
表示t时间上的特征信息的关注度,
表示按元素相乘。本研究所构建的A-BiGRU模型具有一个注意力机制层、一个双向GRU层以及三个全连接层。其中,双向GRU层的神经元为8,激活函数为Relu函数;三个全连接层的神经元分别为48、32和2,前两个全连接层的激活函数为Relu函数,最后一个全连接层的激活函数为Softmax函数。为了防止过拟合,分别在前两个全连接层后加入0.5的Dropout层。
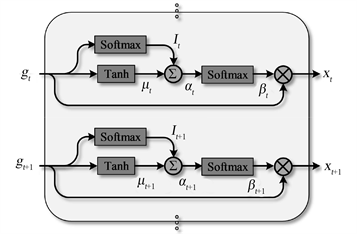
Figure 3. The detailed structure of the designed attention mechanism
图3. 所设计的注意力机制详细结构
2.4. 基于稀疏自动编码器的特征降维
研究表明,手工所提取的全局特征并不能有效地表示用户的签名,通过特征压缩以保留较为重要的特征信息可以有效地缓解这一问题 [12]。相较于主成分分析(principal component analysis, PCA)、线性判别分析(linear discriminant analysis, LDA)等线性的特征降维技术,自动编码器(auto encoder, AE)模型具有良好的非线性表达能力,可以高效的实现复杂数据的压缩降维。
如图4所示,AE模型由输入层、编码器、隐藏层、解码器和输出层组成。尽管在输出层对输入数据进行了完美的重构,但由于输入层在隐藏层的简单映射而导致的特征提取效率低下仍然是AE模型的一个缺点。作为AE模型的延伸,SAE模型通过引入稀疏惩罚项来对AE模型进行改进,从而学习稀疏特征并提高了AE模型的性能 [13]。稀疏惩罚项主要通过约束隐藏层中处于“激活”状态的神经元个数,来实现稀疏限制。假设
为第j个神经元的激活度,那么对于输入的全局特征Y的激活度可以表示为
。假设具有n个样本数据的平均激活度为
,则
可以用下式表示:
(10)
随后,本研究使用Kullback-Leibler (KL)散度来对平均激活度
进行惩罚,其公式如下式所示:
(11)
式中,当
时,KL散度为0。此外,KL散度会随着
和
之间的差异增大而增大。因此,在整个数据集中,可以通过设置参数
来最小化KL 散度以达到抑制大部分神经元的目的,其公式如下式所示:
(12)
式中,
为稀疏惩罚项。本研究所构建的SAE模型的隐藏层的神经元为16,所有层均将Relu函数作为网络的激活函数。
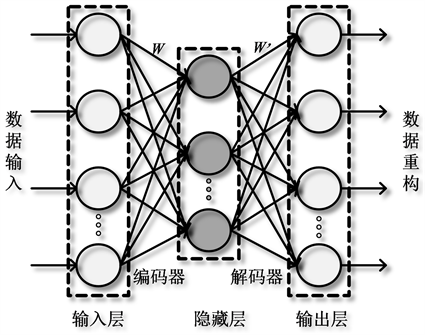
Figure 4. The detailed structure of the auto encoder
图4. 自动编码器的详细结构
2.5. 基于多任务学习的训练方法
本研究分别构建了无监督、有监督以及深度度量三种学习任务的损失函数,并对三种损失函数进行结合以构建用于训练MT-A-BiGRU模型的多任务损失函数。每种损失函数的设计如下所示:
无监督学习任务:本所构建的SAE模型以最小化输入和输出的重构误差为目的,通过无监督的学习方式来进行训练。本研究将均方误差(mean square error, MSE)损失函数作为无监督学习任务的损失函数来进行训练,并在此基础上添加了稀疏惩罚项。无监督学习任务的损失函数如下式所示:
(13)
式中,M为样本数量,
为输入的数据,
为网络所重构的数据,
为稀疏惩罚项系数。
有监督学习任务:本研究所构建的A-BiGRU模型使用交叉熵损失(cross-entropy loss, CEL)函数来进行网络的有监督学习。有监督学习任务的损失函数如下式所示:
(14)
式中,M为样本数量,k为分类数量,
为真实标签,
为网络所预测的分类概率。
深度度量学习任务:考虑到在线手写签名类内的不稳定性,这使得真假签名之间的界限较为模糊。为了使得网络能够在有限的签名样本中更好地学习到签名序列的判别性特征,本研究将深度度量学习中的三元组损失 [14] (triplet loss, TL)作为A-BiGRU模型的第二个学习任务。通过使用半难三元组(semi-hard triplets, SHT)样本来使得三元组损失更好地进行训练,SHT样本可以由下式表示:
(15)
式中,L表示不同类型样本之间的距离,
表示anchor样本,
表示positive样本,
表示negative样本,K表示
大于
的边界参数。
,
,
三种类型的样本均为A-BiGRU模型的倒数第二个全连接层所输出的特征向量。深度度量学习任务的损失函数如下式所示:
(16)
式中,M为样本数量。
多任务学习:在网络的训练过程中,本研究将SAE模型隐藏层所输出的特征向量与A-BiGRU模型第一个全连接层所输出的特征向量进行融合,以实现不同类型特征之间的信息互补并为两种网络模型的共同学习建立联系。同时,将上述三种任务的损失函数相结合,构建了针对MT-A-BiGRU模型的多任务损失函数。MT-A-BiGRU模型的多任务损失函数如下式所示:
(17)
式中,
、
以及
分别表示无监督学习损失函数,有监督学习损失函数以及深度度量学习损失函数的权重。至此,本研究所提出的MT-A-BiGRU模型构建完毕。
3. 实验分析
3.1. 超参数寻优结果
在研究中,神经网络的超参数寻优、训练和验证实验主要是在Python (版本:3.7)平台的Tensorflow(版本:2.0.0)深度学习库上进行。为了使得MT-A-BiGRU模型能够更好地收敛,我们采用Adam优化器,并通过B_1,B_2,Epsilon以及Decay来控制网络学习过程。在保证网络模型收敛且不过拟合的前提下,进行多次迭代训练并选取训练过程中验证率最高的模型权重作为最终训练好的模型。MT-A-BiGRU模型的详细超参数如表1所示。

Table 1. The Hyperparameter optimization results of MT-A-BiGRU model
表1. MT-A-BiGRU模型的超参数寻优结果
B_1、B_2、Epsilon为Adam优化器中的参数,它们分别表示一阶矩估计的指数衰减率、二阶矩估计的指数衰减率以及模糊因子,Decay表示每次训练迭代的学习率衰减。
3.2. 实验结果分析
通过MT-A-BiGRU模型来对40个用户的签名样本分别进行训练,以生成依赖于用户的签名认证模型。本研究使用MT-A-BiGRU模型中的Softmax层所输出的后验概率来对签名验证的准确率,如果后验概率大于0.5则判定为真签名,后验概率小于0.5则判定为假签名。最终,模型的总体验证结果达到了96.88%。错误认证的用户统计结果如表2所示,从中可以看出40个用户中只有11个用户存在认证错误的情况,而其余大部分用户均实现了100%的认证准确度。
Table 2. The user statistical results of error verification
表2. 错误认证的用户统计结果
另外,通过消融实验来进一步分析MT-A-BiGRU模型的多任务学习性能。通过删除MT-A-BiGRU模型的SAE模型以构建基于双任务学习的注意力机制双向门循环单元(dual task learning-attention mechanism-bidirectional gate recurrent unit, DT-A-BiGRU)模型。同时,在DT-A-BiGRU模型的基础上删除深度度量学习任务以构建基于注意力机制双向门循环单元(attention mechanism-bidirectional gate recurrent unit, A-BiGRU)模型。三种模型的对比结果如表3所示,从中可以看出,相较于DT-A-BiGRU模型和A-BiGRU,MT-A-BiGRU模型的准确率达到了96.88%,等错误率(equal error rate, EER)达到了2.16%,取得了最佳的认证性能。三种模型的受试者工作特征(receiver operating characteristic, ROC)曲线如图5所示,从中可以更直观的看出MT-A-BiGRU模型的ROC曲线更接近于原点,并具有最低的EER。这进一步证明了多任务学习可以有效地提高模型的认证性能。
Table 3. Comparison of verification results of different models
表3. 不同模型的认证结果对比
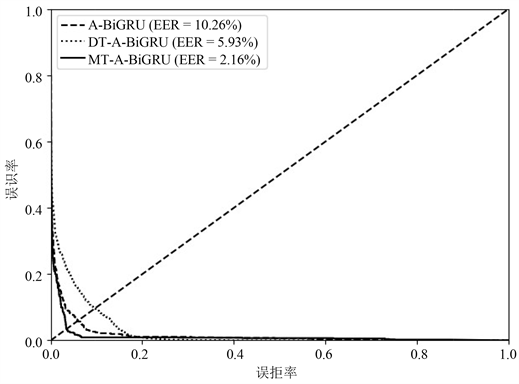
Figure 5. Comparison results of ROC curves of different models
图5. 不同模型的ROC曲线对比结果
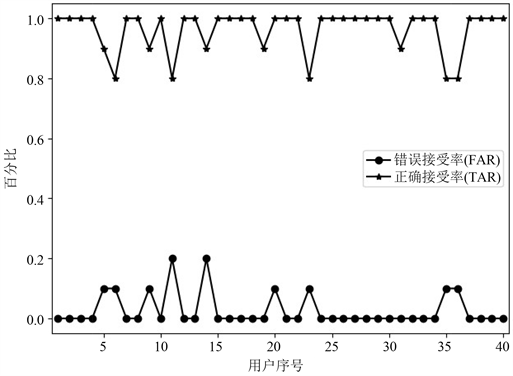
本研究在MT-A-BiGRU模型的基础上删除了注意力机制层构建了基于多任务学习的双向门循环单元(multi task learning-bidirectional gate recurrent unit, MT-BiGRU)模型,以探究所设计的注意力机制对模型性能的影响。两种模型的错误接受率-正确接受率(false accept rate-true accept rate, FAR-TAR)曲线如图6所示,从中可以看出MT-A-BiGRU模型使得用户的FAR在0~0.2之间变化,TAR在0.8~1.0之间变化。相较于MT-BiGRU模型,MT-A-BiGRU模型的抖动幅度更加平稳,FAR曲线更加趋近于0,TAR曲线更加趋近于1。这说明注意力机制层能够有效地提取签名序列中相对稳定且有用的特征信息,从而缓解了双向GRU表征学习的压力。
 (a)
(a)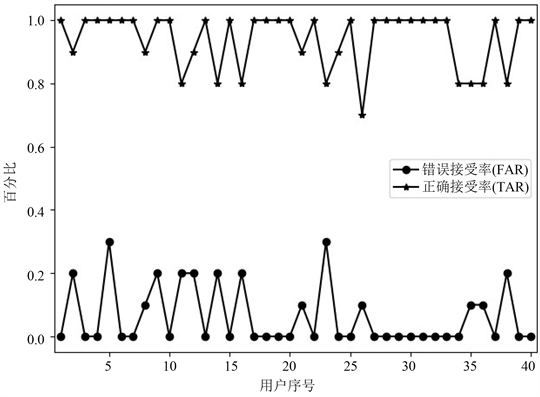 (b)
(b)
Figure 6. Comparison results of FAR-TAR diagrams of the two models: (a) is MT-A-BiGRU model; (b) is MT-BiGRU model
图6. 两种模型的FAR-TAR图对比结果:(a)为MT-A-BiGRU模型;(b)为MT-BiGRU模型
本研究通过一致的流形逼近和投影(uniform manifold approximation and projection, UMAP)算法来对人工所提取的全局特征(47维特征)以及MT-A-BiGRU模型所提取的网络特征(32维特征,该特征为网络中第二个全连接层所输出的特征)进行降维可视化。前四个用户的两种模型的UMAP可视化如图7所示,从中可以看出,人工所提取的全局特征在同类别中分布较为分散,并且异类之间的界限较为模糊。相较于人工所提取的特征,MT-A-BiGRU模型能够更好地区分真签名和假签名样本,并使得真假签名的特征分布距离更远。这充分体现了MT-A-BiGRU模型可以提取人工无法提取的判别性特征。
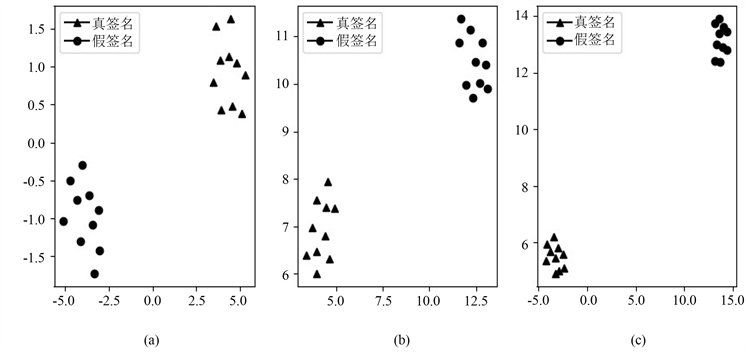
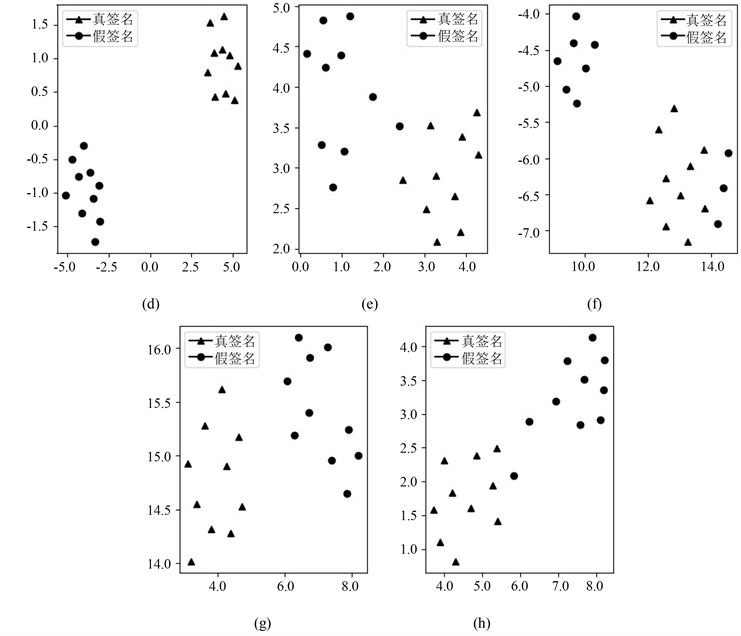
Figure 7. The UMAP visualization of two models. (a)~(d): the dimensionality reduction and visualization of the features of the first four users extracted by the MT-A-BiGRU model; (e)~(h): the dimensionality reduction and visualization of the features of the first four users extracted manually
图7. 两种模型的UMAP可视化。(a)~(d):MT-A-BiGRU模型所提取的前四个用户的特征降维可视化;(e)~(h):人工所提取的前四个用户的特征降维可视化
表4为前人的不同方法在SVC-2004-task2数据集中的实验结果。这些方法与本研究的实验方案相同,均是使用10个真签名和10伪造签名来进行训练。从表4中可以看出,本研究所提出的方法取得了2.16%的等错误率,其性能达到了较为先进的研究水平。在认证性能方面,相较于前三种传统的模式识别方法,所提出的MT-A-BiGRU模型的等错误率实现了大幅降低,进一步体现了深度学习算法的优势。在认证模型方面,基于多任务学习的训练方式可以使得网络更加充分地挖掘签名的判别性特征。同时,稀疏自动编码器和注意力机制能够有效地提高网络自动筛选特征的能力。综上所述,本研究的方法与前人的研究方法相比具有一定的优势。
Table 4. Comparison of the proposed method with previous methods
表4. 所提方法与前人方法的比较
4. 结论
本文提出了一种基于多任务学习的深度学习算法以实现在线手写签名的认证,这是多任务学习技术在该领域的首次应用。基于多任务学习的训练方法弥补了传统单一学习任务无法有效挖掘签名判别性特征的不足。此外,注意力机制和稀疏自动编码器通过对特征的筛选提高了网络捕获签名有效信息的能力。实验结果表明,所提出的MT-A-BiGRU模型可以将等错误率降低到2.16%,有效地提高了签名认证的精度。相较于前人的工作,本研究所提出方法的性能有所提升,进一步证明了该方法的先进性。
基金项目
国家自然科学基金面上项目(62073227)。
NOTES
*通讯作者。