1. 引言
目标检测是计算机视觉领域的重要研究方向,在很多实际应用中都发挥了关键作用。例如:在印刷行业需要利用目标检测来进行印刷品检验,航行管理需要利用目标检测检验设备安全,自动驾驶需要利用目标检测实时监测路面状况等等。随着各种移动终端设备的普及,人们开始利用以终端为载体的目标检测来满足日常生活中的检测需求。目前,已有的算法主要分为传统、基于深度学习的两种类型的目标检测算法,对于传统目标检测算法的采用率已经逐渐降低了,传统目标检测算法也被称为是“两阶段算法”,主要是依靠人工或是算法寻找到目标对象的某种属性特征,依赖目标对象的特征来实现算法的检测,较为常见的传统算法有:Viola Jones检测器、HOG检测器,以及基于部件的可变形模型等等。基于深度学习机制的目标检测算法也被称为“一阶段算法”,大致可以分为两类:一是基于选定区域的目标检测算法,二是基于回归的目标检测算法。以目标检测算法发展史的时间为轴,“二阶段方法”在前,“一阶段方法”在后。“二阶段方法”因为其处理过程分为提取和检测两个阶段而得名,比较著名的“二阶段方法”是诞生于2014年的CVPR R-CNN [1] 算法,该算法逐一对候选区域进行特征提取,对于一些重叠区域进行特征提取时。会造成大量的计算冗余,从而影响计算速度。YOLOv5算法为“一阶段方法”,“一阶段方法”是基于“二阶段方法”的技术进步,“一阶段方法”在基于前者的算法基础上,去掉了提取选定区域特征的步骤,直接进行回归计算。Redmon等人在2016年时首次提出了YOLO算法,标志着单阶段目标检测的时代来临。此后YOLOv系列算法蓬勃发展,从YOLOv0只能做单目标检测,到YOLOv3基本确定YOLO的基本思路,再到改进后的YOLOv5已经拥有较为成熟的网络结构,并拥有良好的检测效果。YOLO系列算法以轻量级网络立足,适用于各种数据集的目标检测。但检测算法如何在基于小数量级数据集的基础上,进行提升检测效率的同时保证良好的检测性能,是亟待解决的问题。
结合小数据集的特点和利用单阶段YOLO系列算法的实时性和准确性,采用了YOLOv5算法中最为轻型的网络结构YOLOv5s结构进行改进,充分利用其优势。解决了小数据集特征数量窄少,目标对象针对性差,以及分类精度欠佳等问题,有效提高了小数量级数据集目标检测的精度,主要创新点包括以下几项:
一为了解决小数据集特征数量欠佳,分析了深度学习网络模型中的数据增广的原理,在不引入额外数据集的情况下增加数据多样性。提出了可以多种数据增广方式叠加,将FMix [2] 模块引入数据增广部分,以加强特征融合。
二是将轻量型SimAM [3] 和CBAM [4] 注意力模块引入网络结构,在不增加目标检测参数量的情况下提升检测性能,进一步改进模型的实时性与识别精度。
三是尝试Adam [5] 、Adamw [6] 、SGD [7] 不同的优化算法对于检测效果的影响。在确保检测网络实时性的前提下,最终得到最优化效果。
2.基本原理
2.1. YOLOv5算法的基本结构
YOLOv5 [8] 算法模型是单阶段算法,主要是通过主干网络直接提取不同层次所拥有的高级特征,再通过使用多级融合网络将位置信息和高级语义信息进行充分融合,最后采用回归算法计算,从而实现目标检测的最终目标。YOLOv5算法机构简洁,如图1所示,主要可分为四个部分:输入端、主干网络、neck网络部分以及输出端部分。YOLOv5算法是在YOLOv3算法结构上进行的进一步修改,YOLOv5算法分有四种结构:YOLOv5s、YOLOv5x、YOLOv5m、YOLOv5l。其中,YOLOv5s模型所带来的检测性能较为突出,且其为最轻型的网络结构。
2.2. 输入端
输入端部分主要是针对数据进行了数据增强、自适应锚框计算以及自适应图片缩放等操作。数据增强部分采用了Mosaic方法,综合了以往数据增强方式的优势,采取了随机排布、随机裁剪、随机缩放等等操作。增加训练样本数量,提升模型训练的鲁棒性。经过数据增强后的数据特征更具有随机性和不确定性,有利于提升数据集的复杂度。自适应图片缩放操作时会产生图片填充黑边,而过多的图像黑边会造成计算冗余,拖慢检测速度。自适应锚框计算针对此种情况进行了算法改进,在对原始图像进行缩放操作时会参考图像本身的尺寸,使得计算量得到减少,从而提高目标检测的速度。
2.3. Backbone主干网络
Backbone主干网络包括Focus结构和CSP (Cross Stage Partial Network) [9] 结构。Focus结构最为关键的是切片操作,将特征图进行切片处理后,再进行卷积操作。在YOLOv5s中,Focus结构使用了32个卷积核进行卷积操作。而CSP结构在YOLOv5s中有两处应用,分别在Backbone主干网络和Neck部分。利用CSP结构可以增强网络的学习能力,持续轻量化网络结构,提高检测准确性,降低计算的内存成本。
2.4. Neck部分
YOLOv5算法在Neck层采用了自顶而下的FPN (Feature Pyramid Network) [10] 结构和自上而下的PAN (Path Aggregation Network) [11] 结构。FPN通过上采样操作,采撷高层语义信息与底层相融合。PAN结构通过下采样操作,采集底层的特征信息传至高层,以便输出预测的特征信息。YOLOv5s的Neck部分设计是为了充分利用Backbone [12] [13] 主干网络所提取的特征信息,传达强语义特征,保证目标特征的提取检测。
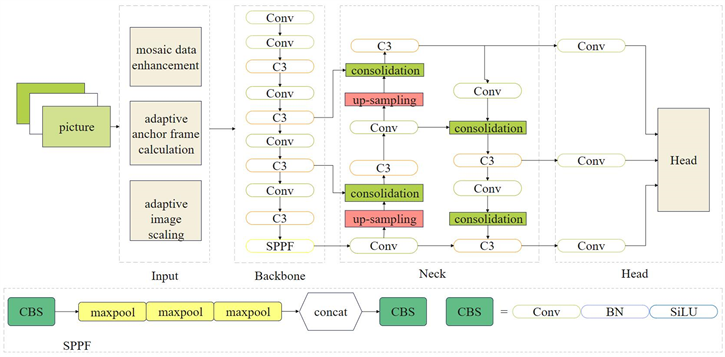
Figure 1. YOLOv5 basic network structure
图1. YOLOv5基本网络结构
2.5. FMix算法模块
数据增强方式可以大致分为两类:基础数据增强和高级数据增强。基础数据增强包含Rotation、Translation等几何数据增强方式,以及Cutout、GridMask是侧重于图像特征视觉外观的非几何数据增强方式,还有Mixup、CutMix等图像混合数据增强方式。高级数据增强中最具代表性的就是自动数据增强,可以分为基于强化学习、非强化学习、风格迁移、特征空间四个部分。
FMix [2] 是非单图像的混合数据增强算法,由Ethan Harris等人提出。FMix算法是基于CutMix算法进行的改进,不仅保留了模型对真实数据的良好理解能力以及可以通过动态增加降低数据集合的过拟合风险,还改进了CutMix算法困限于固态矩形框。如图2所示,FMix算法采用更加柔和的拼接方式,从而保证图像的局部一致性,提高特征语义信息的保留率。
引入了FMix模块使得数据特征可以得到更好地融合,进一步扩展网络学习的数据特征数量。FMix算法是一种混合样本数据增强,先从beta分布中获取lambda (λ)值,再从傅里叶空间低频采样其灰度掩码,对其进行二值化处理,最后利用该掩码对像素进行加权。计算公式如下所示:
(1)
(2)
式中,表示为复数随机变量,表示为衰减功率,表示为离散傅里叶反变换,表示其输入的实部,表示与离散傅里叶变换相对应的样本频率的大小。然后将灰度图像转化为具有阈值的二进制格式掩码,具体公式如下:
(3)
将相关参数值和输入变量进行计算掩码混合函数:
(4)
x1,x2是输入图片,为计算得出的二进制格式掩码,最后将输入图像进行拼接处理,输出最终目标图像,如图2所示:

Figure 2. Image of the data enhancement effect processed by adding the FMix algorithm
图2. 加入FMix算法处理后的数据增强效果图像图示
2.6. 注意力机制
计算机视觉中所应用的注意力机制 [14] (Attention Mechanisms)是模仿人类视觉在大脑皮层的注意力机制 [15] ,可以更快速高效地分析复杂场景信息。注意力机制可以看作是检测网络对于输入图像的重要特征信息的筛选过程,注意力机制的提出是计算机视觉技术的一次飞跃发展,可以提高运算结果的性能。注意力机制按照侧重权重的不同大致可以分为:通道注意力机制、空间注意力机制、时间注意力机制、分支注意力机制,还有两种混合注意力机制:通道空间混合注意力机制和空间时间注意力机制。
FSC-YOLOv5s算法引入了两种注意力机制:CBAM注意力机制和SimAM无参数注意力机制,将两种模块分别插入Backbone [16] 主干网络和Head部分,以增强目标检测效果的性能。
CBAM (Convolutional Block Attention Module)是一个简洁高效的前馈卷积神经网络注意力模块。如图3所示。CBAM包含两个相互独立的子模块,分别是通道注意力模块(Channel Attention Module, CAM)和空间注意力模块(Spartial Attention Module, SAM),如图4、图5所示。这两个模块可以并行或是串行的方式组合,先利用通道注意力模块,再采用空间注意力机制,可以更好地提升网络结构的性能。
CBAM模块的计算流程是先对主干网络生成的特征图产生1D通道注意力特征图和2D通道注意力特征图,如公式5、6所示。分别沿着通道和空间注意力模块推算注意力权重,然后再将所得到的权重和输入的特征图相乘,进行自适应特征优化。
(5)
(6)
式中,
,
,
。
SimAM [17] 注意力机制是一种简单有效的3D注意力模块。CBAM模块类似于人脑的注意力机制,会在估计1D和2D的注意力权重后,再将其结合起来。所以CBAM注意力机制并不会产生真实的三维权重。而SimAM注意力机制 [18] 可以有效地产生真实的三维权值。在SimAM模块 [19] 的计算中,需要单估每个神经元的重要性,估算前需要找到这些神经元,测量目标神经元与其余神经元之间的线性可分离性,对于每一个神经元的能量量化,SimAM以公式7为计算函数。
(7)
式中,
,
和
为转换的权重和偏置。
通过最小化公式7,可以找到目标神经元t与同一通道中其他神经元之间的线性可分离性。对yt和y0采用二进制标签,添加一个正则化器。每个通道在理论上都有M = H × W个能量函数,最终的能量函数为公式10所示。
(8)
其中,
。
因此,可以用下面公式计算最小能量。
(9)
综上所述,神经元的能量越低,其重要性越高。每个神经元的重要性可以通过计算
得到。使用缩
放算符来进行特征细化,sigmoid是一个单调函数:
(10)
通过结合SimAM注意力模块,可以提升检测算法的性能。
2.7. Adam、Adamw、SGD优化算法
Adam [20] 优化算法,是一种梯度下降优化算法的扩展,又称之为自适应运动估计算法,由Diederik Kingma和Jimmy Lei Ba提出。Adam优化算法加速了优化过程,具有高效的计算效率,对于计算内存要求较小,适合应用于计算数据和或是参数调节的问题,适用于计算梯度较为稀疏问题。Adam优于传统的随机梯度下降算法不同的是,它可以随着展开学习行为的进程,参考每一个网络权重参数,从而单独调整相对应的学习速率,从梯度的第一次和第二次矩值估算来计算不同参数的自适应学习效率。
假设一个存在一个有噪声的目标函数
,运用Adam优化算法计算目标函数,mt定义为动量,vt可以理解为梯度变化的方差,分别是gt的一阶矩估计向量和二阶矩估计向量。计算第t步梯度的一阶矩估计向量mt和二阶矩估计向量vt分别是:
(11)
(12)
Adam算法主要是在RMSprop的基础上增加了动量,并进行了偏差修正。修正之后,在时刻t的一阶矩估计量和二阶矩估计量分别是:
(13)
(14)
对于式中参数,可以设置参考值为
。
综上所述,Adam优化器可以根据计算梯度的震荡情况和过滤震荡后的真实梯度对变量参数进行实时更新。
Adamw优化算法包括权重衰减与L2正则化,是在Adam算法和L2正则化的基础上进行改进的算法。L2正则化是减少过拟合的经典方法,对于优化器中的阶梯函数,需要使用梯度修正参数,在计算的时候会加上对正则项求梯度的结果。Adamw函数与Adam函数直接加上L2正则项不同,不是在损失函数的位置直接加上L2正则项,而是将正则项的梯度加入反向传播的公式中,代替在损失函数处添加正则项的操作。如下式所示:
(15)
综上所述,Adamw函数是基于Adam函数的基础上产生的变体,用于处理大型数据集。Adamw函数以一定比率来缩减模型参数的梯度,从而减少计算量,提升训练速度。
SGD是一种最简单的优化算法。它采用了最简单的梯度下降法,随步更新梯度,算法的收敛速度限制于学习率。SGD优化算法结构简单,没有过多的参数需要调整,较少的计算量可以获得较好的计算结果。其原理如下式所示:
(16)
式中,W表示为更新的权重参数,η表示学习率。
3. 分析与讨论
3.1. 实验设置
实验平台由某云服务器提供,使用GPU配置为NVIDA GeForce RTX 3080,采用CUDA 11.1加速库进行实验并加速,采用基于python3.8的PyTorch深度学习框架实现。为了保证实验的实时性以及公平性,各个模型输入图像尺寸均为640 * 640,batch size设置为16,epoch设置为200,使用Warm up和余弦退火的学习率衰减,初始学习率为0.01,动量为0.937。
3.2. 评价指标
实验所用的检测精度的评价指标选用mAP50-95值(mean Average Precision),代表IoU阈值为0.95时各个类别AP的均值。mAP值表示所有类别的平均精度值(Average Precision, AP)的平均值。在实验中将精确度和召回率作为检测效果的辅助参考指标。P为准确率,在预测中该值理想状态为1,R为召回率,在预测效果中的理想状态为1。其计算公式如下:
(17)
(18)
式中,TP [21] 为正确分类的正样本数,FP为误报的负样本数,FN为漏报的正样本数。以下实验分别使用两个自建数据集进行实验测试。
3.3. 数据增强实验
数据增强 [22] 是深度学习对于数据预处理采用的一种较为常见的扩充数据的方法,对于训练时参考数据集的数量级较小,数据增广方法可以在不引入额外的数据集的情况下,在现有的数据集现状上增加训练数据量,降低数据采集成本。改进YOLOv5s网络模型,在原先算法基础上引入FMix算法。
如表1所示,加入FMix结构后,在数据集1的实验中,P值提升了15.6%,R值微值浮动,AP50-95值提升16.5%。数据集2的R值提升了4.3%,AP50-95值提升1.3%。引入FMix结构,可以在不加入额外数据集的情况下增加训练数据特征量,对目标对象的检测效果的精度也有一定的提升效果。FMix处理后的数据特征图,在模板融合时选择了任意形状,而非是固定的矩形方块,保留了更多的语义信息分布,使其更加适合针对小数据集的数据增强。

Table 1. Comparison of the quantitative results before and after the addition of the FMix module
表1. 加入FMix模块前后的定量结果对比
3.4. 优化器选择实验
实验针对Adam优化器、Adamw优化器、SGD优化器进行了对比实验论证。根据实验效果数据,选择出最适合的优化算法。
从表2中的结果对比可知,在参数量和计算量基本没有发生改变的情况下,引用SGD优化算法使得模型检测精度达到较好效果。在两个数据集的实验中应用SGD优化器都比应用Adam、Adamw优化器的检测精度高,数据集1采用SGD优化器的AP值分别比采用Adam优化器和Adamw优化器提高了60.3个百分点和49.8个百分点。数据集2采用SGD优化器的AP值分别比采用Adam优化器和Adamw优化器提高了13.5个百分点和28.5个百分点。可以看到,数据集2采用SGD优化器的检测效果比其余两种要更好,其P值、R值、AP值、AP50-95值均得到提升。因此,据实验结果显示,选择SGD优化算法是最有利于提升检测性能。
Table 2. Optimization algorithm module comparison experiment
表2. 优化算法模块对比实验
3.5. 注意力模块对比实验
为了验证注意力模块对目标检测算法的有效性以及探究注意力模块的最佳嵌入方式,设计了对比实验。在以上实验的基础上,针对加入CBAM模块的位置以及是否加入SimAM模块进行了探究。
表3中CBAM_L1、CBAM_L2、CBAM_L3对比可得,不同位置插入CBAM注意力模块,效果会不同。在三种嵌入方式中,第三种嵌入方式明显优于其余两种,即在Backbone的每一个卷积层后都加入一个CBAM注意力模块。在数据集1上,选择CBAM_L3方案的AP值比CBAM_L2提高8.3%,比CBAM_L1的AP值提升20.5%,而且CBAM_L3方案的P值为三种方案中最高值,其R值为1。CBAM_L3方案是三种植入注意力模块方案中效果最好的一种,所以在原网络的Backbone主干网络中引入CBAM注意力模块,且在特征提取部分加入注意力机制可以更好地提取特征,提升检测性能。
Table 3. The CBAM attention module contrast experiment
表3. CBAM注意力模块对比实验
YOLOv5s网络中的Head部分主要包含了三个检测器、损失函数部分以及Head侧的优化策略,即利用网格的锚框在不同尺度的特征图上进行目标检测的过程。在Head部分引入SimAM无参数注意力机制,可以提升目标检测精度。实验结果如表4所示,在数据集1的表现上,于Head部分引入无参数注意力机制SimAM后,AP50-95提高了3.8%。在数据集2的实验中,AP50-95提升了5.9%。较之前实验效果来说有显著提升。实验发现在不同部分引入不同注意力模块,对于深度学习网络都有正向增益效果。
Table 4. Attention module lateral contrast experiment
表4. 注意力模块横向对比实验
由表5的消融实验可知,引入FMix算法,用以数据增强。在Backbone部分引入CBAM注意力模块,在Head部分引入SimAM无参数注意力机制,选择适合的SGD优化器,会使得P值和R值达到一个相对理想状态的数值,且AP50-95值得到提升。因此,FSC-YOLOv5s网络结构有效提升了小数量级数据集的算法性能。
4. 结论
针对目标检测任务中数据集数据量薄弱对目标检测造成困扰的问题,提出引入FMix算法,以增强训练数据样本,同时引入了CBAM以及SimAM注意力模块,增强了网络模型对于目标特征提取能力,提高了模型的计算速度。选择了SGD优化算法,提出的改进模型对在不加入额外的学习参数的情况下,与原网络结构在小数量级的数据集上检测效果相比有了显著性提升。FSC-YOLOv5s算法可以继续推广在动态图像的目标检测领域,尝试在较高速或是图像固定时长较短的类型视频上,以提升其检测精度和加快其检测速度。
基金项目
北京印刷学院科研创新团队项目:面向按需出版的彩色高精度喷墨印刷系统关键技术研究(20190122019)、北京印刷学院学科建设和研究生教育专项:电子信息研究生实验实践教育深化改革与质量提升项目(21090122012)、北京印刷学院校级项目(Ec202303)、北京印刷学院校级项目(Ea202301)、北京市数字教育研究重点课题(BDEC2022619027)、北京印刷学院学科建设与研究生教育专项(21090323009)。
NOTES
*通讯作者。